Yüksek Hacimli Sorgular için Local LLM Kullanımı
Local LLM'leri yüksek hacimli sorgu altında verimli sunmak için vLLM, PagedAttention ve continuous batching tekniklerini kullanın; KV cache israfını yüzde 4'ün altına çekerek 2-4x throughput sağlayın.
Local LLM'leri yüksek hacimli sorgu altında verimli sunmak için vLLM, PagedAttention ve continuous batching tekniklerini kullanın; KV cache israfını yüzde 4'ün altına çekerek 2-4x throughput sağlayın.

Bir SaaS platformu ya da müşteri destek robotu günde binlerce LLM isteğini işlediğinde, kendi sunucunuzda çalıştırdığınız local LLM'ler de geleneksel servis altyapıları gibi hızla darboğaza girer. Sorunun kalbinde KV cache var: modelin önceki token'lara ait ara hesaplamalarını sakladığı GPU belleği. Cache büyüdükçe hafıza parçalanır, boşa ayrılan alan ortaya çıkar.
UC Berkeley araştırmacılarının vLLM çalışmasına göre, klasik "her sorguya tek parça bellek ayır" yaklaşımı yüzde 60-80 oranında KV cache israfına yol açar. Buna bir de statik batching (sorguları sabit gruplar halinde çalıştırma) eklendiğinde uzun bir sorgu kuyruğu kilitler, kısa sorgular GPU boş dururken sırada bekler.
Local LLM'i yüksek hacimde verimli sunmanın yolu: bellek yönetimini ve kuyruk mantığını yeniden tasarlamak. vLLM bu iki problemi birden çözen açık kaynak local LLM sunucusudur.
vLLM, local LLM çalıştırmak için tasarlanmış açık kaynak bir inference sunucusudur. İki temel yeniliği var: PagedAttention ve Continuous Batching.
Klasik sunucular her sorgu için baştan sonra büyük bir bellek bloğu ayırır. Sorgu bitince bu bloğun yarısı boş kalır, başka sorgu için kullanılamaz. vLLM ise işletim sistemlerindeki sayfalama mantığını model belleğine uyarlar: KV cache'i sabit boyutlu küçük "sayfalara" böler. Sayfaların bellekte yan yana olma zorunluluğu yoktur; boşalan bir sayfa anında başka sorgu için kullanılabilir. Sonuç: israf yüzde 4'ün altına iner.
Bonus: aynı sistem prompt'undan türeyen farklı kullanıcı çıktıları, ayrışana kadar aynı sayfaları paylaşır. RAG veya few-shot prompt kullanan local LLM kurulumlarında bu, ciddi VRAM kazancı demek.
Statik batching'de bir grup sorgu birlikte başlar, en uzunu bitene kadar GPU diğer slot'larda boşa çalışır. vLLM ise her token üretimi sonrası biten sorguyu çıkarır, yerine kuyruktaki bir başkasını hemen ekler. In-flight batching denen bu yaklaşım GPU'yu sürekli dolu tutar; özellikle uzunlukları çok değişken sorgularda (sohbet, OTP doğrulama, kısa öneri vb.) throughput'u belirgin şekilde artırır.
Tek seçenek vLLM değil. İki alternatif local LLM sunucusu öne çıkıyor:
Üretimde sıklıkla şu seçim yapılıyor: standart local LLM dağıtımı için vLLM, kapalı/regüle ortamda en yüksek tek-GPU performansı gerektiğinde TensorRT-LLM.
Yüksek hacimli LLM sunumunda PagedAttention ve continuous batching ne kadar kritikse, yüksek hacimli SMS gönderiminde de queue yönetimi ve concurrent request handling o kadar belirleyici. iletiMerkezi SMS API'si toplu gönderimleri kuyruklayıp operatöre dağıtırken benzer ilkelerle çalışacak şekilde tasarlanmıştır: kısa OTP'lerin uzun toplu kampanyaların arkasında bekletilmemesi için öncelik kuyrukları, retry/backoff politikaları ve rate-limit mekanizmaları altyapının bir parçası (ayrıntılar için SMS API dokümantasyonu). Local LLM'inizin kullanıcıyla SMS üzerinden temas kuran kısmını iletiMerkezi MCP Server veya doğrudan REST API ile entegre edebilir, hibrit mimari kurarken iletişim kanalını dert etmeden yapay zeka tarafına odaklanabilirsiniz.
Yüksek hacimli sorgular için local LLM kullanımı, doğru sunucu seçildiğinde kendi veri merkezinizde bile rahatlıkla mümkün. vLLM'in PagedAttention ve Continuous Batching çözümleri, bellek yönetimini işletim sistemi düzeyindeki sayfalama mantığıyla optimize ederek GPU kullanımını maksimize eder. Geleneksel LLM sunucularındaki yüzde 60-80 bellek israfı yüzde 4'ün altına iner, throughput 2-4 kat artar. SaaS ekipleri için sonuç: binlerce eş zamanlı kullanıcıyı düşük gecikmeyle yanıtlayabilen, ölçeklenebilir bir local LLM altyapısı. KVKK ve GDPR uyumu ise yine süreç tarafına bağlı; erişim kontrolü, log yönetimi, veri saklama/silme politikaları ve sözleşmesel gerekliliklerle birlikte kurgulandığında bu altyapı uyum gerekliliklerini karşılamayı kolaylaştırır.
Detaylı dokümantasyon ve örnek kodlarla dakikalar içinde entegre edin.

Geliştiriciler
KVKK ve GDPR çerçevesinde verilerini şirket içinde tutmak isteyenler için local LLM rehberi: Ollama, LM Studio, GPT4All, LocalAI ve Jan ile Llama 4, Qwen3, Gemma 3 modellerini yerel olarak çalıştırma.
Devamını oku
Geliştiriciler
FLUX.2, LTX-2 4K, HunyuanVideo 1.5, CogVideoX, Wan 2.1, Open-Sora ve Stable Diffusion gibi açık kaynak modellerle yerel olarak video ve görsel üretmek; donanım planlaması ve KVKK uyumlu içerik akışı.
Devamını oku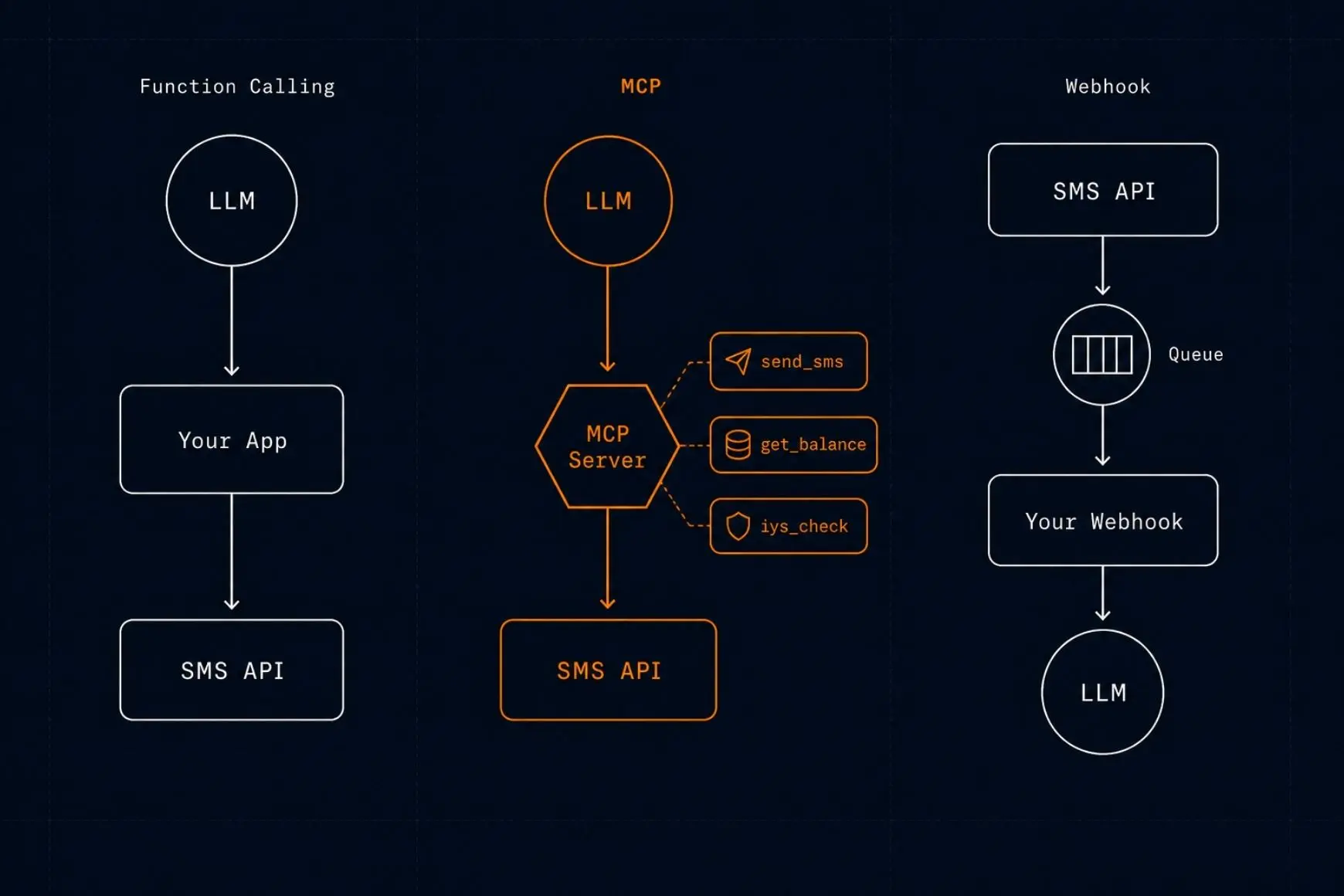
Geliştiriciler
AI ajanlarına SMS gönderme yeteneği eklemenin üç yolu: function calling, MCP, webhook. Her birinin ne zaman doğru seçim olduğu, kod örnekleri ve karşılaştırma tablosu.
Devamını oku